Tableau Server on AWSのベストプラクティス
BIアプリケーションとして、Microsoft Power BIとSFDCのTableau は人気を二分しています。
Tableau のサーバサイド製品であるTableau ServerのAWS導入時のベストプラクティスを実体験をもとに示していきたいと思います。また、Tableau ONLINEとの比較やQuickSightとの比較も実体験をもとにしていきたいと思います。
Tableau ServerのAWS導入時の全体構成とEC2
Tableau としても下記をヘルプページに乗せておりますが、少し教科書的な部分があります。
Amazon Web Services に Tableau Server をインストールする - Tableau
Tableau Serverはシングルノード構成、HA構成の大きく二つがあります。(Act Standbyの構成もありますが、シングルノード構成の延長のため割愛)
各構成でのAWSダイアグラムを下記に示します。いずれも基本はEC2ですが、大きなポイントを列挙します。
※データベースとしてRedshiftを載せていますが、他のデータベースでもOKです。ただ後述しますが、Redshiftがおすすめです。
- ドライブを複数にする事がポイントです。最低でも、OS用のEBSと、Tableau Serverインストール用のEBSです。そして、シングルノード構成や3HAのInitial NodeではTableau Serverのバックアップファイル保存用にもう1ドライブつけることが小さいですがポイントになります。(S3にこのバックアップファイルをUploadする事がほとんどだとは思いますが)
- シングルノード構成や3HAのInitial NodeにはEC2のAutoRecoveryを設定します。これは、耐障害性を高めるためです。
- インスタンスタイプは公式のページにもあるように、Rシリーズがおすすめです。
- WindowsServerを利用する場合、Windowsの動的ポートの拡張を行います。
https://kb.tableau.com/articles/issue/tableau-server-port-exhaustion-problems?lang=ja-jp
シングルノード構成

- 3HA構成の時には、ロードバランサを利用するとおもいますが、SSL(HTTPS)の終端と、StickySessionのONは設定するのが望ましいです。ただし、Tableau 純正の性能試験ツールであるTabjoltを利用する場合、StickySession=OFFとHTTPのリスナーをロードバランサで設定する必要があります。
HA構成(3ノード構成)
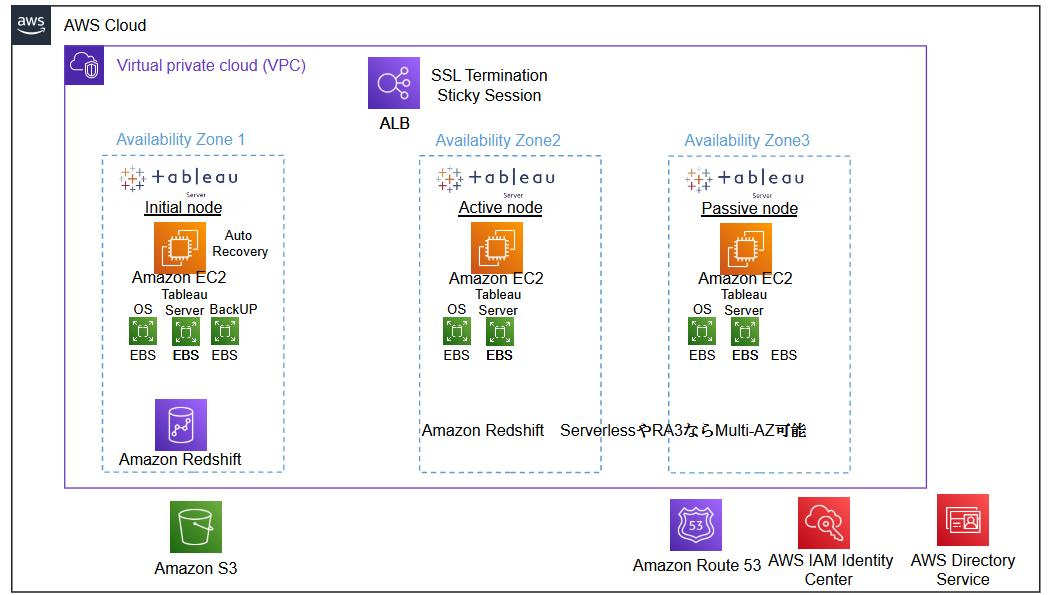
Tableau ServerでのLIVE接続 vs Hyper(抽出)
Tableau Server ではレポートに使用するデータベースを都度接続するか(Hyper)、あらかじめ抽出するか(Hyper)から選択できます。
AWS設定上のではいずれの接続でもPrivateLinlk設定ですが、両者は以下の特徴があります。
- LIVE接続
- オンライン:即時制のあるデータを利用可能。オンラインレスポンスは劣る
- バッチ:抽出のバッチが不要
- Hyper(抽出)
- オンライン:即時制のあるデータは利用できない。オンラインレスポンスは早い
- バッチ:抽出のバッチが必要
上記に加え、AWS利用上の注意点としては、データベースインスタンスは稼働時間にたいして課金がされます。つまり、Hyper(抽出)においてはバッチ実行時のみにデータベースを利用する事がコストメリットが大きいです。これとベストマッチするのは、Redshift Serverlessです。
ですので、Redshift Serverless+Tableau Server のホスティングが現時点では最も良い構成と思われます。
QuickSight vs Tableau Server
機能面ではQuickSightとTableau では差が大きいために、単純な比較はできないものの、非機能や構成面で比較したいと思います。
QuickSightを利用する場合の構成は下記になります。サーバレスであるために、非常にシンプルです。また、スケールを意識しなくてよいのは大きなアドバンテージです。
AWS内でデータが閉じるのもよい点です。
一方で、QuickSightがサポートするのは抽出(SPICE)のみですが、Tableau であればバッチ記述が必要な更新をスケジュール設定できるのは、大きな強みです。
QuickSightは「ちょっとBIを試したい」というニーズには大きく適合すると思われます。

ReInvent2021 待望のRedshiftServerlessを深堀
RedshiftServerless爆誕
ReInvent2021にてRedshiftServerlessが発表されました。待望のserverless製品です。
RedshiftはこれまでもRedshift Spectrumを出していましたが、今回のServerlessはどのように違うのでしょうか。また、同じserverlessであるAhtenaとはどのように異なるのでしょうか。
机上調査
Redshift ServerlessはDWH製品らしくRDBMSライクに高性能・多機能に使えます。
Ahtenaは多様なデータを簡易に探索できる事が強みに見えます。

とりあえず回してみる
ということで、下記の構成にて比較検討してみました。

性能結果はこちらです。概ね、RedshiftServerless>Ahtenaですが、注目に値するのは、2回目以降のRedshift Serverlessの速さです。

Amazonの見解を見てみる
Amazonのには下記です。確かに、上記調査や試行を結果を裏付けるような記載です。
Redshift では、これらのクエリを非構造化データ用に最適化されているクエリサービスと比べて最大 20 倍高速で実行します。非常に大規模な多数のテーブル間で多数の結合がある、高度に構造化されたデータに対してクエリを実行する必要がある場合は、Amazon Redshift をお勧めします。
これに対して、Amazon Athena のようなクエリサービスを使用すると、データの形式化やインフラストラクチャの管理について心配することなく、Amazon S3 のデータに対して直接インタラクティブにクエリを実行できます。例えば、Athena は、一部のウェブログですばやくクエリを実行し、サイトのパフォーマンス問題のトラブルシューティングのみが必要とされる場合に適しています。クエリサービスを使用すると、迅速に開始できます。データのテーブルを定義し、標準 SQL を使用してクエリを開始するのみです
https://aws.amazon.com/jp/athena/faqs/
結論 Redshift Serverlessしか勝たん
Redshift ServerlessはRedshiftを使ってきた人にとっては、最高です。Query Editor v2もかなり使いやすいです。(TPCDS,TPCHのテストデータがついたのも、地味に良い)
Redshift Serverlessは他のクラウドDWH製品を明らかに意識した作りであり、部分的な優劣は見られますが、これまでの弱点を解消し、真打ち登場といった感じです。
はやくGAしてほしいです!
AWS朝会 データレイク・レイクハウス アーキテクチャ
資料をSlideShareにあげましたので、ご参考にしてください。



データサイエンティストになるために数理的な教養・知識は必要ですか?
さまざまなポストで、色々なデータサイエンティストになるための本が紹介されていたりします。
これらは大変素晴らしく思うのですが内容はだいたい大学の専門教育課程でバシバシ出てくるようなはっきりって専門書が多いのです。これらは確かに必要だと思う反面、多くのデータサイエンティストになりたいと思われるエンジニアや社会人が読んで理解できる内容かと言うと疑問がつくのも思うのです。一方でデジタルという文脈の中、こういった知識を持たずに活躍されている方も散見されます。実際に現場で働く人間としてこの点をディープタイプしていきたいと思います。
私の持論
持論としては、ハイレベルなデータサイエンティストのうちアルゴリズムを考えるようなエンジニアになりたいなればこのような知識は深いレベルでの理解が必須です。
非常に詰まったような言い方になりました。
日本の悪しき情報システム開発文化とデータサイエンスへの影響
何が言いたいかと言うと、現在のいわゆる情報システム開発運用の現場では全くコンピューターのこと知らない人がでも活用できています。これは日本特有の下請けシステムプロジェクトマネジメントシステムによるものが大きいと思います。
情報システム開発においてコンピューターサイエンスを全く知らなくてもコミュニケーション能力だけで開発できるという、ある意味日本の独特の発明が日本の情報システム開発の現場は根強く残っています。そしてデータサイエンスの分野でもこれは非常にいろこく反映されております。
データサイエンス協会というところが発行している人材像を見ています。
これは、人材像はざっくり言いますと3タイプに分かれています

個人的にはこの3つ全てをハイレベルで持っていることが大事だと思うんですが、なかなかそうはいかない事情があるとおもいます。
なのでそれぞれの特性にあわせまして3つに役割分担するというのはまぁある意味納得のあるものです。(このあたりがデータサイエンスの多様性でありつつも、数理的素養をもたない人達を量産している遠因だと思うのですが)
そしてその中で一番というかほど独占的に数理的な素養が必要な人たちがデータサイエンス力をもってモデリングをする人たちです。
この人たちは主に統計だったり機械学習のアルゴリズムを知っている必要があり、それを業務適用する実装を考えなくてはいけないので、データサイエンスのど真ん中の人たちだと思います。
今から10年ぐらい前の情報システムにおいては統計パッケージが存在したものを機械学習パッケージというのはかなり限られていたために自分で実装する必要がありました。
しかし現代においては chainer や tensorflow 、DataRobot のようなAutoML と言った機械学習の知識があまりなくてもモデリングができてしまうソフトウェアでも非常に多いです。
コミュ力おばけの逆襲
そしてこれらのソフトウェアというのは多くがブラックボックス化されております。そのためなぜこうなったのか所も説明がしにくいという特徴があります。ここが最大のポイントです。
仮に非常に数理的な素養を持った人であってもこういったソフトになった勝手な想像の域を出ないため多分こうなったみたいな話になるわけです。
そうなるとうっすら知識を持ち、ハイレベルコミュニケーション能力の人がいればこのへんは何とかなってしまうわけです。
また自分でプログラミングする必要があるプロジェクトもあると思いますが、もし、これをプログラミングを外注できるようなプロジェクトだった場合、お客に説明する説明責任というのはハイレベルコミュニケーションを持っているけど中は何も知らないみたいな人です。そしてもちまえの圧倒的コミュ力でなんとかなってしまっている状況は生まれてしまいます。
そして日本の現場ではこれをチーム力というふうに参照する文化がありますので、そもそもこの点は問題視されるということ自体がそもそも少ないです。
さらにアルゴリズムの数理的理解においては「アカデミックでいいじゃん」という風になるわけです。そうなると、数理的な大学教養レベルの本というのは趣味の領域を出なくなってしまいます。そしてこれで仕事が回ってしまう現実もあります。
ここまではSIerのような観点で話をしましたが、いわゆる事業会社でも同じような事がやっぱり起きています。 事業会社の場合は、ビジネスを前に進めることが主目的なので別に中身としたらどうでもいいわけです。一方でSierや開発会社とかそういったところで上記のような状態になると日本のデータサイエンスレベルの底上げには繋がるものの、 スピードが遅い理由です。伝統的な SIerだと、そもそも上層部データサイエンスと冬の開発になんていなかったりそもそも何もしらなかったのでもっと自体は悪かったりします。(これらの企業も何もしていないわけではないですがやはりスピードは遅いです)近年の機械学習 AI のスタートアップが流行しているのもこういったところが背景になると思います。
自学の現実解
大学3、4年の教養レベルを学び直すの大変なストレスです。想像してみてください、自分と全く違う領域の4年生レベルのテキストをぽいとわたされて「これ理解しておいてね一週間後までに」って言われたら普通の人は絶望すると思います。
これがさも当然と言われているのはこのデータサイエンスの領域の恐ろしい点だとおもいます。
もちろんこれは現場の話であります。その社を代表するようなサイエンス人材であったり業界を代表するような入れるような人物であれば数理的理解としてはあるべきと思います。
そうは言ってもある程度、ハイレベルなコミュニケーションの人でも話せるぐらいの知識はこの業界の人万人が持つべきだと思うので、機会を見て紹介していきたいと思います。
IPA ITストラテジストに合格する勉強法の話(直前対応)
はやいものでもうすぐ試験です
コロナによる影響はIPA試験も例外でなく、ITストラテジスト試験も紅葉と寂しさをかじる秋から、新緑と期待に満ち溢れる春に変わりました。
I気が付けばのこり一週を切ったので、わたくしめの体験と対策を記します。
ITストラテジスト試験とは
ITストラテジスト試験は、上流工程の構想策定を役割とし、取得により労働基準法における専門職として認められる唯一の情報処理技術者試験の区分であり、同試験の最高峰といわれる試験です。受験者の平均年齢も一番高いです。
ITストラテジスト試験の要
高度区分のため論文試験(午後2)が出題されますが、他の区分よりも採点が厳しいのが最大の特徴です。他の論文試験過去 PM や IT アーキテクトなどで合格できるレベルの論述があってもITストラテジスト試験では落ちることはよくあります。(B判定のまま、、等)
ですので、ITストラテジスト試験は「日本語の問題」という側面があるのですが、それだと「てにをは」や「表現か」と勘違いされる方もいらっしゃるかもしれませんので、これを具体的に言いますと「いかに問題文の意図に沿って論述するか」にかかっています。
この一言でこの試験の攻略方法を語り尽くした気がしますがきちんと説明をしたいと思います。
論文試験(午後2)Deep dive
午後2問題の問題文の流れはおおむね下記です。
- 課題の状況設定
- 課題の制約条件
- 課題解決の方向性
ITストラテジスト試験において非常に大事なことは、
この問題文で書かれている問題文の流れを、できるだけ問題文に近い状況にアレンジして書く必要があります。
ですので、過去問を4,5回書きながら、問題文の流れにあっているかをひたすら確認する事が鉄則です。
加えて午後2問題は3題から1題選択ですが、じつはこれもどのようなジャンルかパターン化してしまってます。
- 情報システムの全体システム化構想
- 個別情報システム化構想
- 組み込みシステム企画
おそらく普通のエンジニアは個別情報化システム化構想と全体システム化構想でどちら選ぶかと思います。
これを選択する基準として「企業におけるビジョン」が感覚的にどれほど自分にとって理解し論述できるかにかかります。いずれも必要ですが、全体システム化構想のほうがビジョンの理解と記述は論述に求められます。
ビジョンとは何だ
ビジョンというのは
その会社の経営の経営理念
経営上の最も基本の方針
と考えています。具体例で見ましょう
ファーストリテイリングです。
ではこれを実現する上での具体的な計画は何?となると、それが中期経営計画です。
中期経営計画を実現するために、事業計画があり、この事業計画全体をITで支えるものが全体システム化構想です。事業計画の個別テーマをITで支えるものが個別システム化構想です。
これに注意して経営との整合を論述する事が非常に大切です。
結局どれくらい勉強すれば
よく質問されることがありまして必要な練習時間はどれぐらいですかと聞かれたりします。人によるので難しいんですけれども、概ね 他の高度情報試験の勉強期間×2 と思ってくださればよいと思います。
そうはいっても直前なんですけど!
そのような方でも、落ち込まないでください。
なるべく有利に試験するための心得を3つ言います。
1:解答する大問をあらかじめ決める。
前述の通り大問の傾向は決まっています。ご自分の得意で決め打ちしてください。これで解答時間を10分は節約できます。
2:おきにいりの筆記用具を用意する。
本番の120分は指が痛くなるくらいに文字を手書きします。特にラスト15分は一心不乱です。自分にとって書きやすい筆記具を用意しておいてください。
3:「問題文の意図に沿って論述する」トレーニングだけする。
これが論述の要です。論文を書く時間がなくても、過去問を見て、問題文とその論調をつかってどのように自分のエピソード(創作含む)を書くか、メモ書きや音読でもいいので少しでもやっておきましょう
Redshiftしか勝たん!② Redshiftの悪魔的進化
あなたのRedshift、開発してからそのままではないですか?
「Redshiftは同時実行に弱い」
「RedshiftはMaterized viewがない」
「RedshiftはマルチAZできない」
そう思っているひと、いませんか? いや結構いるはずです。
そして、Redshift推しの開発者なら、伝統的なDB感をもつAP担当者と、そのGAPについて侃侃諤諤した事があるはずです。
Redshiftが別物といえるほど進化しました
数々のGAPを抱えてきたRedshiftですが、ここ数年で圧倒的に進化しました。
数がおおすぎるので、私めにてまとめたのが以下です。

「Redshiftが一時停止できるようになった」事は有名だと思いますが、実はこれだけの超進化がおきたのです。
さすがRedshift!しびれる、あこがれるゥ